Seattle Rain
You’re about to get on a plane to Seattle. You want to know if you should bring an umbrella. You call 3 random friends of yours who live there and ask each independently if it’s raining. Each of your friends has a 2/3 chance of telling you the truth and a 1/3 chance of messing with you by lying. All 3 friends tell you that “Yes” it is raining. What is the probability that it’s actually raining in Seattle?
Facebook interview question posted on Glassdoor.
Most answers posted on the link above are:
which is the probability that all friends say it is raining provided that it’s true… but we are interested in the opposite, the probability that it is raining provided that all friends say that.
Another common answer is based on a correct idea:
where
is a binary event, so:
But those answers then mix joint and conditional probabilities, getting yet a wrong result (which is correct only if the probability of rain in Seattle is ):
is not the joint probability that all friends say the same thing (it is raining) and that is true, but the probability that all friends say that it is raining conditional on the fact that it is raining.
Let’s consider the two extreme cases to confirm that the solution above is not always correct. If it is always raining in Seattle,
If it never rains in Seattle,
The tricky part of the problem, since we may be biased to think that the solution is fixed, is that there is an unknown parameter (, the probability of rain in Seattle), which the solution depends on. We need to apply the Bayes’ theorem, which states that the posterior probability (the probability of an hypothesis conditional on a given body of data (the evidence, ) can be calculated as:
Let the probability that one friend tells the truth. Then, if there are friends:
We are told that is the number of friends and that . Hence:
Let’s see what the posterior probability would be for a few possible values of the prior probability:
Also, note that the posterior reaches a value of for a prior as low as .
Let’s confirm that the solution above is right, simulating the problem in R (for all possibles values of from to , in steps of ):
library(dplyr)
set.seed(12345)
# Simulate N cases for each probability of rain in Seattle (p)
# in the whole [0, 1] range, in steps of 0.05
N <- 5e3 # simulations (per value of p)
q <- 2/3 # prob of a friend telling the truth
data <- data.frame(p = rep(seq(from = 0, to = 1, by = 0.05), each = N))
data <- data %>% rowwise() %>% mutate(r = as.logical(rbinom(1, 1, p))) %>%
mutate(A = as.logical(ifelse(r == 1, rbinom(1, 1, q), rbinom(1, 1, 1 - q))),
B = as.logical(ifelse(r == 1, rbinom(1, 1, q), rbinom(1, 1, 1 - q))),
C = as.logical(ifelse(r == 1, rbinom(1, 1, q),
rbinom(1, 1, 1 - q)))) %>% ungroup()
# p: probability that it is raining in Seattle
# r: it is raining in Seattle
# A, B, C: friend A, B, C says it is raining
# (not to be confused with he or she is telling the truth)
data %>% sample_n(10) %>% print(n = 10) # show 10 of the 21*N rowsSource: local data frame [10 x 5]
p r A B C
<dbl> <lgl> <lgl> <lgl> <lgl>
1 0.70 TRUE TRUE TRUE TRUE
2 0.65 TRUE TRUE FALSE TRUE
3 0.85 TRUE TRUE TRUE TRUE
4 0.90 TRUE FALSE TRUE FALSE
5 0.80 TRUE FALSE TRUE TRUE
6 0.75 TRUE TRUE TRUE TRUE
7 0.95 TRUE TRUE TRUE FALSE
8 0.70 TRUE FALSE TRUE TRUE
9 0.55 TRUE TRUE FALSE TRUE
10 0.60 FALSE TRUE FALSE TRUE
# Check proportions of r (compared to p)
data %>% group_by(p) %>% summarize(Real_Prob_Rain = mean(r)) %>%
rename(Prob_Rain = p) %>% print(n = Inf)Source: local data frame [21 x 2]
Prob_Rain Real_Prob_Rain
<dbl> <dbl>
1 0.00 0.0000
2 0.05 0.0460
3 0.10 0.0978
4 0.15 0.1494
5 0.20 0.1938
6 0.25 0.2466
7 0.30 0.2956
8 0.35 0.3390
9 0.40 0.3934
10 0.45 0.4524
11 0.50 0.4994
12 0.55 0.5430
13 0.60 0.5900
14 0.65 0.6586
15 0.70 0.6908
16 0.75 0.7406
17 0.80 0.8004
18 0.85 0.8504
19 0.90 0.8942
20 0.95 0.9492
21 1.00 1.0000
# Check proportions of friends telling the truth (compared to q)
data %>% rename(Raining = r) %>% group_by(Raining) %>%
summarize("%Cases_All_Friends_Say_Raining" = mean(A + B + C) / 3) %>%
print(n = Inf)
data %>% rename(Prob_Rain = p, Raining = r) %>%
group_by(Prob_Rain, Raining) %>%
summarize("#Cases" = n(),
"%Cases_All_Friends_Say_Raining" = mean(A + B + C) / 3) %>%
print(n = 11)Source: local data frame [2 x 2]
Raining %Cases_All_Friends_Say_Raining
<lgl> <dbl>
1 FALSE 0.3322547
2 TRUE 0.6649218
Source: local data frame [40 x 4]
Groups: Prob_Rain [?]
Prob_Rain Raining #Cases %Cases_All_Friends_Say_Raining
<dbl> <lgl> <int> <dbl>
1 0.00 FALSE 5000 0.3332667
2 0.05 FALSE 4770 0.3243885
3 0.05 TRUE 230 0.6826087
4 0.10 FALSE 4511 0.3302298
5 0.10 TRUE 489 0.6659850
6 0.15 FALSE 4253 0.3359981
7 0.15 TRUE 747 0.6604195
8 0.20 FALSE 4031 0.3304391
9 0.20 TRUE 969 0.6584107
10 0.25 FALSE 3767 0.3342182
11 0.25 TRUE 1233 0.6580157
.. ... ... ... ...
# Filter the evidence: all 3 say it rains
# And group by each value of the prior Prob(it rains), p
data_interest <- data %>% filter(A * B * C == TRUE) %>% group_by(p)
# For each value of the prior (p), what is the posterior?
# (i.e., the mean number of cases where it rain, r == 1)
data_interest %>% summarize(Posterior = round(mean(r), 3)) %>%
mutate(Posterior_Theoretical = round(8*p / (1 + 7*p), 3)) %>%
rename(Prior = p) %>% print(n = Inf)Source: local data frame [21 x 3]
Prior Posterior Posterior_Theoretical
<dbl> <dbl> <dbl>
1 0.00 0.000 0.000
2 0.05 0.279 0.296
3 0.10 0.498 0.471
4 0.15 0.587 0.585
5 0.20 0.643 0.667
6 0.25 0.705 0.727
7 0.30 0.778 0.774
8 0.35 0.814 0.812
9 0.40 0.845 0.842
10 0.45 0.850 0.867
11 0.50 0.900 0.889
12 0.55 0.903 0.907
13 0.60 0.928 0.923
14 0.65 0.949 0.937
15 0.70 0.933 0.949
16 0.75 0.952 0.960
17 0.80 0.974 0.970
18 0.85 0.977 0.978
19 0.90 0.986 0.986
20 0.95 0.995 0.993
21 1.00 1.000 1.000
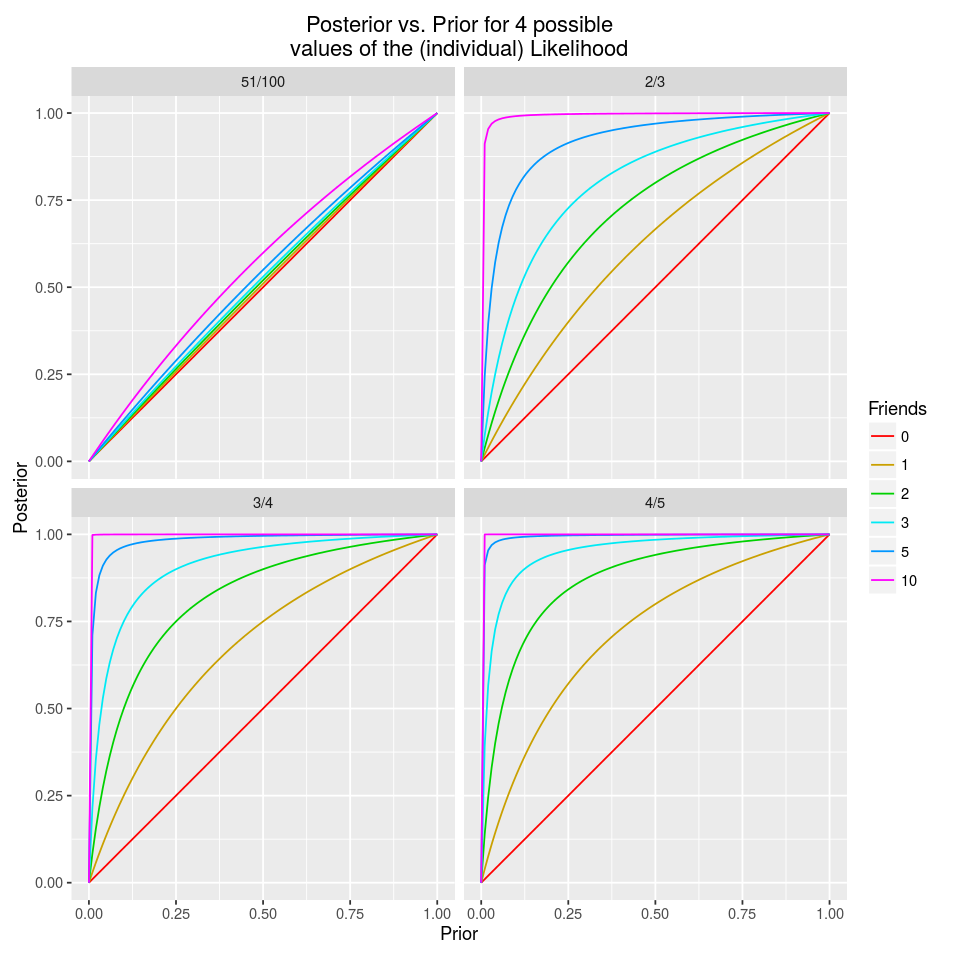
Now let’s consider a more generic case, where not only , but also the number of friends, , and the probability that any of them tells you the truth, , are not fixed. This analysis will give us the morality of this problem, which could be: “Always trust your friends (especially the more you have!), provided that they tell the truth more often than not.”
Without loss of generality, let’s assume that is a positive rational number, and hence can be written as , where . We want to focus on the case where our friends are more likely to tell the truth, so the following condition must hold:
We can write the posterior probability that we want to calculate as:
Since , the limit of the posterior probability as approaches infinity is , regardless of the value of (for ).
I.e., if a sufficiently large number of friends tell you that it is raining in the desert, and the chances that each one of them is messing with you are less than , bring an umbrella with you. For (and ), the posterior is greater than for a prior as low as .
Let’s finish by plotting the posterior against the prior for a few possible values of and (our case of interest, corresponds to the light blue line in the upper-right graph). As expected, if (i.e., we have no evidence), the posterior equals the prior.
posterior_prob <- function(q, N, p) {
q^N * p / (q^N * p + (1 - q)^N * (1-p))
}
p <- seq(0, 1, 0.01)
library(MASS)
df <- data.frame(Prior = rep(p, each = 24),
N = rep(c(0:3, 5, 10), each = 4),
q = c(0.51, 2/3, 3/4, 4/5)) %>%
mutate(Posterior = posterior_prob(q, N, Prior),
Friends = as.factor(N),
Q = factor(as.character(fractions(q)),
levels = as.character(fractions(unique(q)))))
library(ggplot2)
ggplot(data = df, aes(x = Prior, y = Posterior, colour = Friends)) +
geom_line() +
scale_color_hue(c = 240) +
labs(title = paste('Posterior vs. Prior for 4 possible\nvalues of',
'the (individual) Likelihood')) +
facet_wrap( ~ Q, nrow = 2) + coord_fixed()
options(repr.plot.width = 8, repr.plot.height = 8)